`
| |
|
Archive for the ‘legacy code’ Category
Friday, May 18th, 2012
At the last SDTConf, Todd Little facilitated a session called “Technical Debt is Really a Lease.”
I had a few interesting take-aways from this discussion:
- A debt always has a notation that you need to pay it eventually (unless you default.) This is not true in case of a technical debt. There might be parts of your code which is a complete mess, but you don’t touch it and its fine to live with that debt. Or you might just decide to throw away that code since it served its purpose. You might never need to pay off that technical debt.
- Deep down in our psychology, the term “debt” trigger a negative thought. We strive hard to avoid a debt. However if you project the same thing as a lease, it seems to have a more positive feel. In the business world, taking on a lease, in many cases, can give you a good business advantage. In fact some might even consider it to be stupid not to lease out stuff.
- The important thing to consider is: what is the “Cost of Service” for a lease/debt? If the cost is significantly high, you are better off not taking it on. But if the cost is really low, it makes all economical sense to embrace it. We’ve learned that long-term, heavy interest leases/loans are a bad idea for that very reason. But a short-term, low interest loan can provide extra working capital to expand business.
IMHO it can really help teams to think of technical debt really in terms of the “cost of service” of a lease.
Beware not to make technical debt a dumping ground for tasks that the team wants to defer without a conscious, thoughtful reason. I’ve seen in many organizations, technical debt becomes an easy excuse for the team to skip things that are very important but for their short-sighted hasty decisions.
Posted in Agile, legacy code | No Comments »
Tuesday, May 1st, 2012
At the SDTConf, we had an interesting discussion on how to deal with technical debt. The group agreed on the following suggestions:
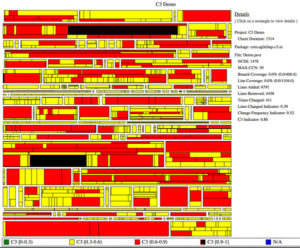
- C3: Coverage, Complexity & Churn – Instead of looking at each of these parameters in isolation, we generate C3 graph using a TreeMap and use the cumulative graph to see red spots in the product. Esp. helpful to quickly raise awareness.
- Slack: Every team members gets a 10-20% time every iteration to invest on things that hurt them.
- Scratch your Personal Itch day: Every iteration each team members gets 1 day to fix unplanned issues on the project
- Visitor from Hell: Every month have one person from other team visit you and give you feedback on various aspect of the team. Its up to the team to address these issues or not. But certainly can be used to pitch to the management for additional time to work on these issue.
- Code Walk Throughs: Every time a team member (or pair) implements something important, they give a code walk through or a demo to the rest of the team. This usually ensures team members don’t have crappy things when they give a demo.
Check out the project rescue report, if you would like to see some examples of how we’ve used C3.
Posted in Agile, Coaching, legacy code, Metrics, Organizational, Training | No Comments »
Friday, March 25th, 2011
I find myself using the following heuristics:
More details: Long Method Smell: When is a method too big?
Posted in Agile, Code Smells, Design, legacy code, Programming | No Comments »
Wednesday, March 9th, 2011
When confronted with Legacy code, we usually run into the Test-Refactor dilemma. To refactor code we need tests, to write tests, we need to refactor the code.
Some people might advise you to invest time upfront to create a whole set of tests. Instead I recommend that every time you touch a piece of legacy code (either to fix a bug or to enhance the functionality), you perform a couple of safe refactoring to enable you to create a few scaffolding tests, then clean up the code (may be even test drive the new code) and then get rid of the scaffolding tests.
Even though this approach might appear to be slower, why does this approach work better?
- You start seeing some immediate returns.
- On any given system, there are parts of the system which are more fragile and needs more attention than others. There are parts of code which we actively touch and others we rarely touch. When we have a limit time, it does not make sense in investing effort to create tests for areas that are fairly stable or rarely changed. Big upfront test creation might not take this aspect into account. So you might not get the biggest bang for your buck.
- The first few tests we usually write are fragile tests. But we won’t get this feedback nor the opportunity to improve the quality of our tests until its too late.
- When we get into a test creation mode, everyone is focusing on creating more and more tests. Finally when we start using the tests we’ve created, a small change in production code might breaks a whole bunch of tests. First few times developers wonder what happened, but if this generates a lot of false-negative (which usually they do), then developers start ignoring or deleting those tests. So the investment does not really pay for itself.
- Also when we have a whole lot of tests prematurely written, they start getting in the way of refactoring and genuinely improving the design of the code. (Defeats the whole point of creating test upfront so we can refactor.)
- People get too attached to the tests they had written (it was a big investment). They somehow want to make the test work. People fail to realize that those fragile tests are slowing them down and getting in their way.
- Unless the team gets into the habit of gradually building better test coverage, they will always play the catch up game with requirements constantly changing. (Remember we are chasing a moving target.)
- Its usually hard to take a fixed (usually long) duration of time off from CRs and bug fixes. People will be forced to multi-task.
I encourage you to share your own experience.
Posted in Agile, legacy code, Programming, Testing | No Comments »
Wednesday, February 16th, 2011
Technical Debt is any technical issues slowing down the project due to hasty (short-sighted) decisions made at an earlier point.
All of us make bad decisions, but not fixing them and just differing them really leads to bigger problems as these issues have a snowball effect.
Technical debt can be introduced at various levels:
- Code smells is the most obvious one,
- But things like lack of (or poor) automation,
- poor choice of tools,
- fragility in the development environment
- and so on
can also contribute to technical debt.
Posted in Agile, Design, legacy code, Programming, Testing | No Comments »
Tuesday, December 22nd, 2009
A lot of developer have a tendency to suggest rewriting legacy code instead of refactoring. Personally I don’t think one approach is better than the other. Following are the issues/issues one needs to consider with each:
Rewrite:
- Difficultly in coming up with Cost and Time estimate. (Its best to pull some numbers off the hat)
- What if new bugs are introduced during rewrite?
- Similarly how do you avoid unintentional behavioral changes?
- What is the guarantee that you won’t end up with the same problems?
- How do you get Management buy-in? Let’s say even if you get Management buy-in, how do you motivate developers to rewrite existing apps?
- While rewriting, we’ll certainly introduce new technologies. How do you deal with problems introduced by new technology?
- How to handle change requests during rewrite?
- How to avoid not over engineering the solution?
- How do you deal with various Political Issues around technology, tools, team, etc.?
- How do you avoid Resume Driven Development?
Refactor:
- How do you deal with Refactor-Test Dilemma (Egg and Chicken problem) ?
- How do you motivate the existing team to continue and refactor code?
- How do you effectively identify the inflection point?
- How to avoid big changes (in the name of refactoring) instead of baby steps?
- It takes quite a lot of time and effort to understand legacy code
- Even while refactoring developers might have a tendency to over engineer (esp. coz most developers conclude that the original developers did not think well and build an extendable solution)
- To Refactor effectively it certainly need developers with higher skill-set. Can you find them?
- Many times you’ll run into difficultly in breaking dependencies. How would you deal with it?
In my experience a thin-sliced hybrid approach seems to work the best both from technical and business point of view. In a subsequent blog I’ll explain what I mean by thin-sliced hybrid approach.
Posted in legacy code | 4 Comments »
Wednesday, August 20th, 2008
Unfortunately most people still measure size of code in number of Lines of Code (LoC). We all know LoC is a professional malpractice. Now, how do you objectively identify a long method? If we are not supposed to count LoC, then how can we define a long method?
Some people say, if the code does not fit in one screen and if you have to hit page down, then the method is long. How many times have you looked at code that fits in one screen, but still felt that code was long? Happens to me all the time.
Joshua Kerievsky says “If one cannot quickly and easily understand what a method does and how the method does it, it is a long method”. I really like this definition. But is a little wage to me and I don’t quite understand the theory behind why and when can something be hard to easily understand.
One approach I’ve found to rationalize long method smell is by using the Single Responsibility Principle (SRP). If the method violates SRP, there is a good chance that its Long Method.
If I need to parse the method’s code more than once, then its a good indication that the method is complicated to understand.
Cyclomatic Complexity can also give some interesting data points to under/measure when a piece of code is long. Usually large methods have a higher CC.
Recently I stumbled upon “The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information“, a 1956 paper by the cognitive psychologist George A. Miller of Princeton University’s Department of Psychology.
In this paper, Miller showed a number of remarkable coincidences between the channel capacity of a number of human cognitive and perceptual tasks. In each case, the effective channel capacity is equivalent to between 5 and 9 equally-weighted error-less choices: on average, about 2.5 bits of information. – Source WikiPedia
What does this mean? In a layman’s world, this means that 7+/-2 is the number of things (concepts) we can hold in our brain. So when I look at a piece of code and if it has more than 9 things in there, it exceeds my brain capacity to hold it in my memory and actually understand what is going on. I often notice that 7 or less things in the code is easy to manage. Once it starts cross that number, its gets exponentially difficult to hold it in my mind and to understand what is going on.
So if you are thinking of deleting elements from an array if they match a set of to-be-deleted elements, then that’s a good method for me. Why? Coz : I have an array, a set, an iterator, a loop, current values, a comparator and a delete operation. Around 7 things. That’s the max I can hold in my brain. But now if all of a sudden you throw thread synchronization into this, I may end up taking the loop, matching the current elements and the deletion out into another method.
So size has nothing to do with LoC, its a measure of related concepts that you need to hold in your brain.
Posted in Agile, Design, legacy code, Programming | 2 Comments »
|



